Publications
A collection of my research work. † denotes equal contribution.
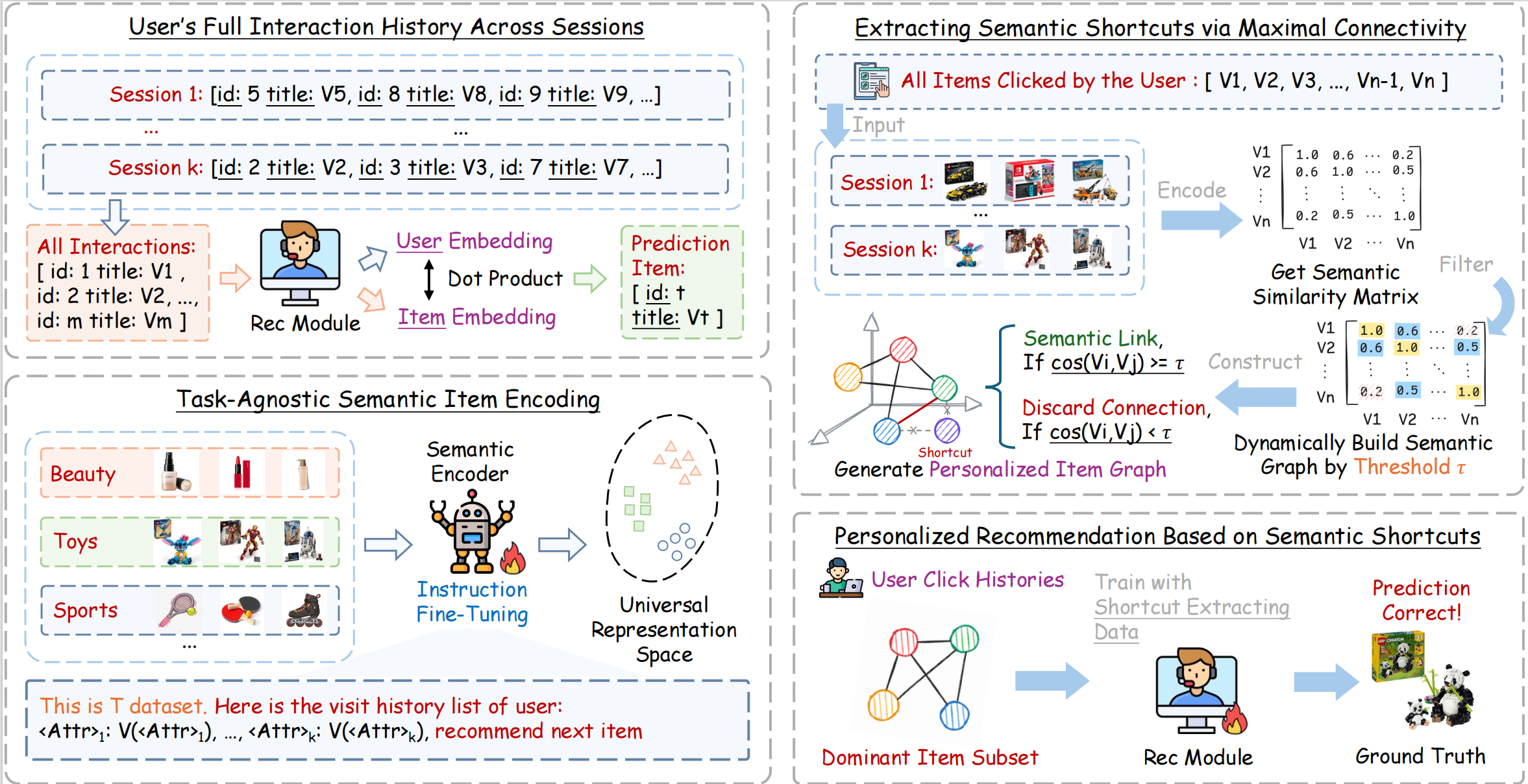
LISRec: Modeling User Preferences with Learned Item Shortcuts for Sequential Recommendation
Haidong Xin, Zhenghao Liu, Sen Mei, Ohters
KDD 2026
This work proposes LISRec, a framework that extracts personalized semantic shortcuts from user histories to filter noise and capture stable preferences, significantly improving sequential recommendation performance.
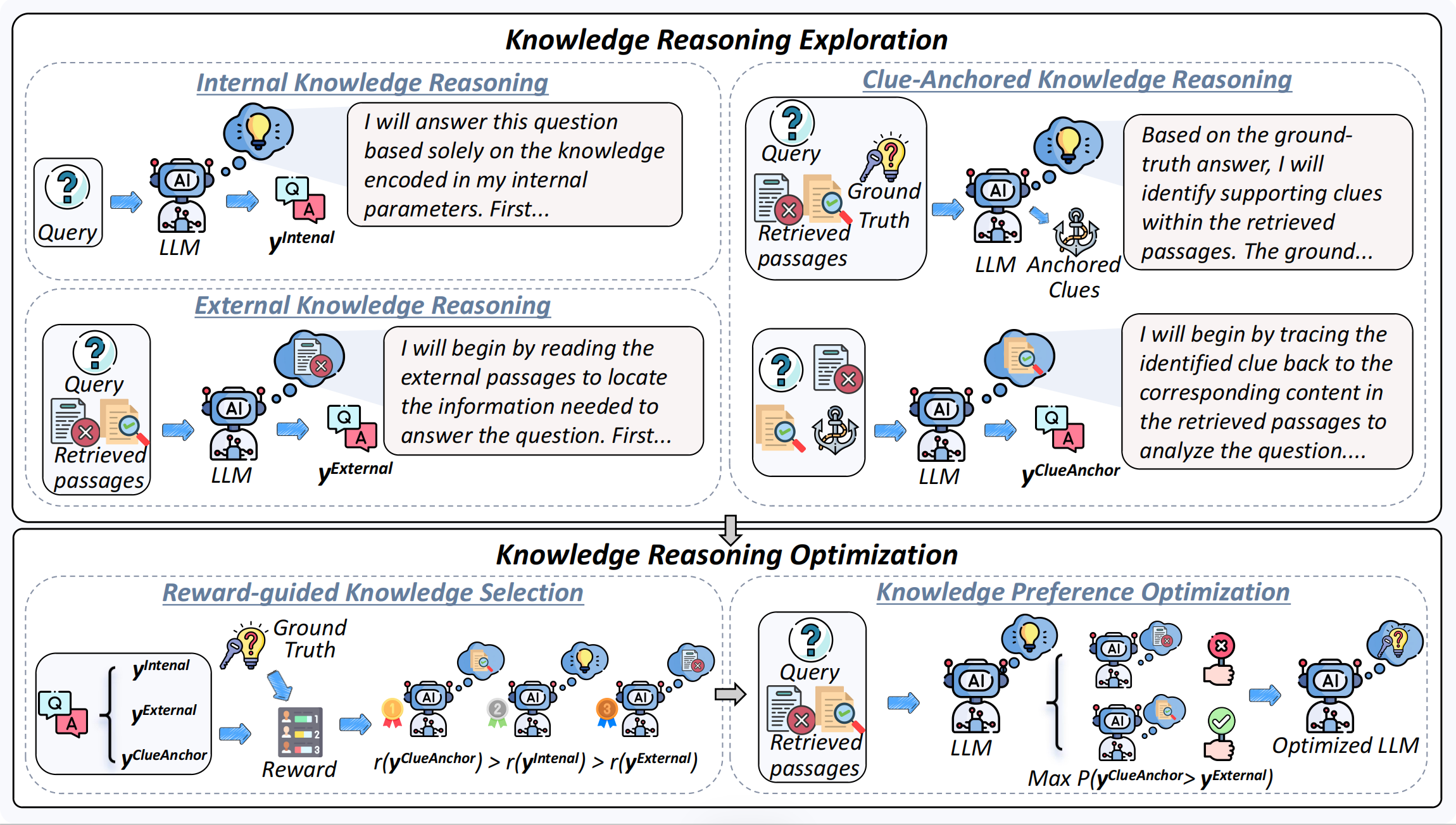
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
Hao Chen, Yukun Yan, Sen Mei, Wanxiang Che, Others
EMNLP 2025
This work introduces ClueAnchor, a clue-anchored reasoning framework that generates and optimizes multiple reasoning paths to help RAG systems better extract and integrate key evidence, yielding more complete and robust reasoning even under noisy or implicit retrieval.
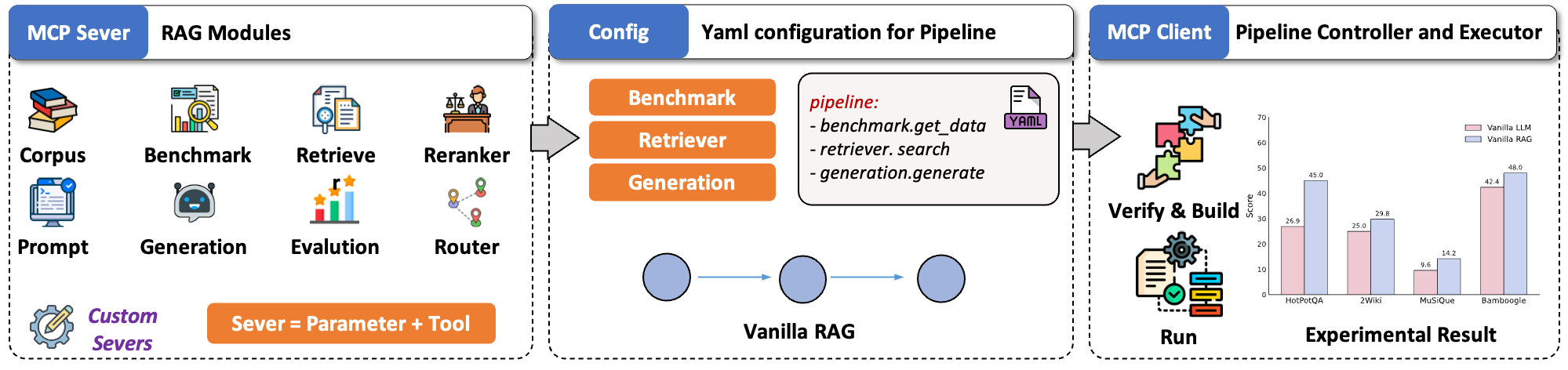
UltraRAG v2: A Low-Code MCP Framework for Building Complex and Innovative RAG Pipelines
Sen Mei, Haidong Xin, Chunyi Peng, Yukun Yan, Others
OpenBMB 2025
A Low-Code MCP Framework for Building Complex and Innovative Retrieval-Augmented Generation systems.
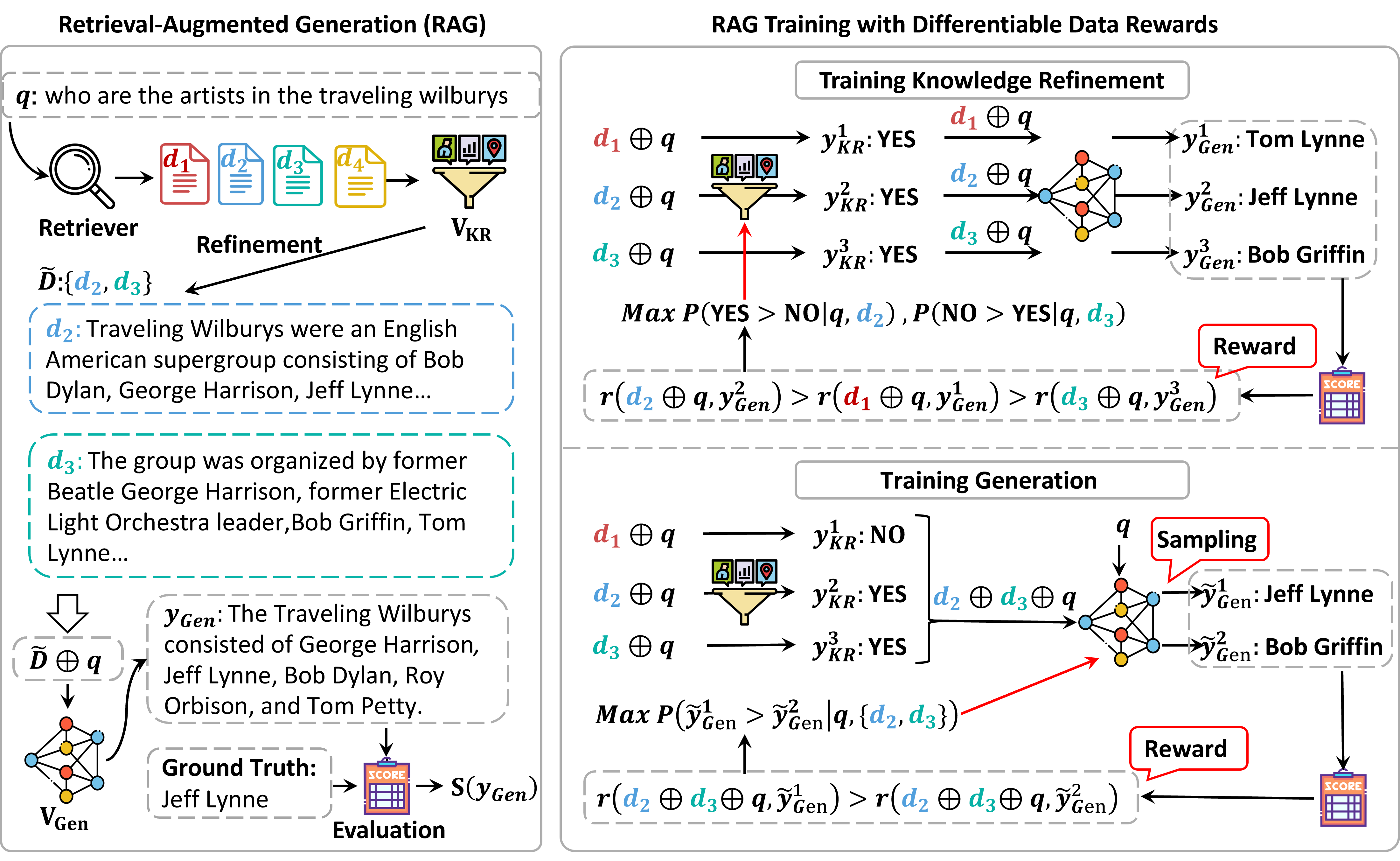
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Xinze Li†, Sen Mei†, Zhenghao Liu, Yukun Yan, Others
ICLR 2025
RAG-DDR is an end-to-end method that aligns RAG modules through data rewards, enabling LLMs to use retrieved knowledge more effectively than SFT.
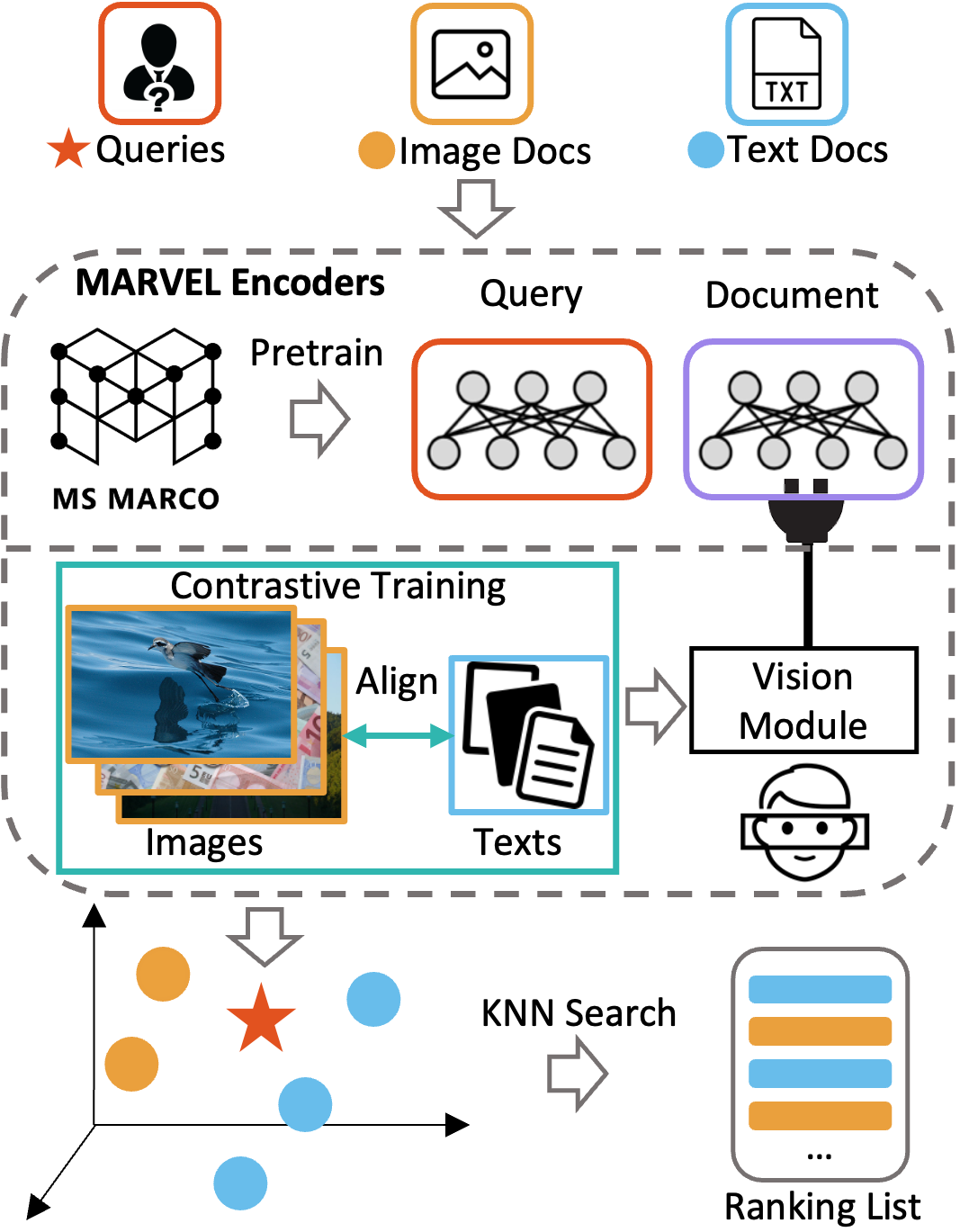
MARVEL: unlocking the multi-modal capability of dense retrieval via visual module plugin
Tianshuo Zhou†, Sen Mei†, Xinze Li, Zhenghao Liu, Others
ACL 2024
MARVEL learns an embedding space for queries and multi-modal documents to conduct retrieval and encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of the well-trained dense retriever, T5-ANCE, by incorporating the visual module's encoded image features as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and extracts the related text and image documents from anchor-linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. MARVEL provides an opportunity to broaden the advantages of text retrieval to the multi-modal scenario. Besides, we also illustrate that the language model has the ability to extract image semantics and partly map the image features to the input word embedding space.
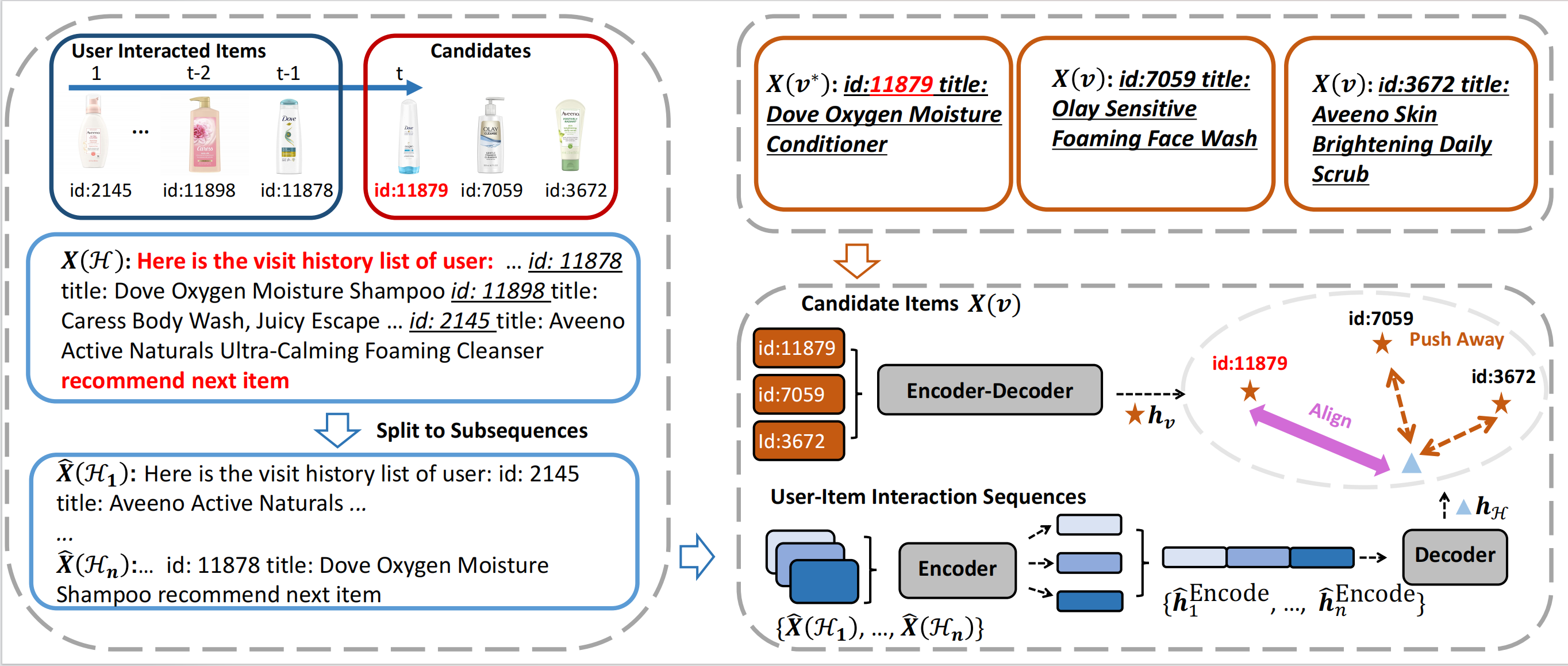
Text matching improves sequential recommendation by reducing popularity biases
Zhenghao Liu†, Sen Mei†, Chenyan Xiong, Others
CIKM 2023
This work introduces TASTE, a text-matching sequential recommendation model that verbalizes items and interactions while using sparse attention to model long histories, achieving state-of-the-art performance and alleviating cold-start and popularity-bias issues.